Technical Deep Dive: Building ChatIBD
Large language models (LLMs) like ChatGPT are impressive generalists, but their breadth is also their limitation. In IBD care, we as clinicians need accurate and reliable information in the flood of guidelines that are published online. We want answers to both simple and complex questions, grounded in trusted guidelines and accurate dosing information.
ChatIBD is designed to use the LLM’s context window differently. Instead of letting the model fill it with its training data (which goes out of date over time), we load it with curated guideline extracts and user context (such as the location you are querying from). This ensures the model reasons from trusted inputs using the best available clinical evidence.
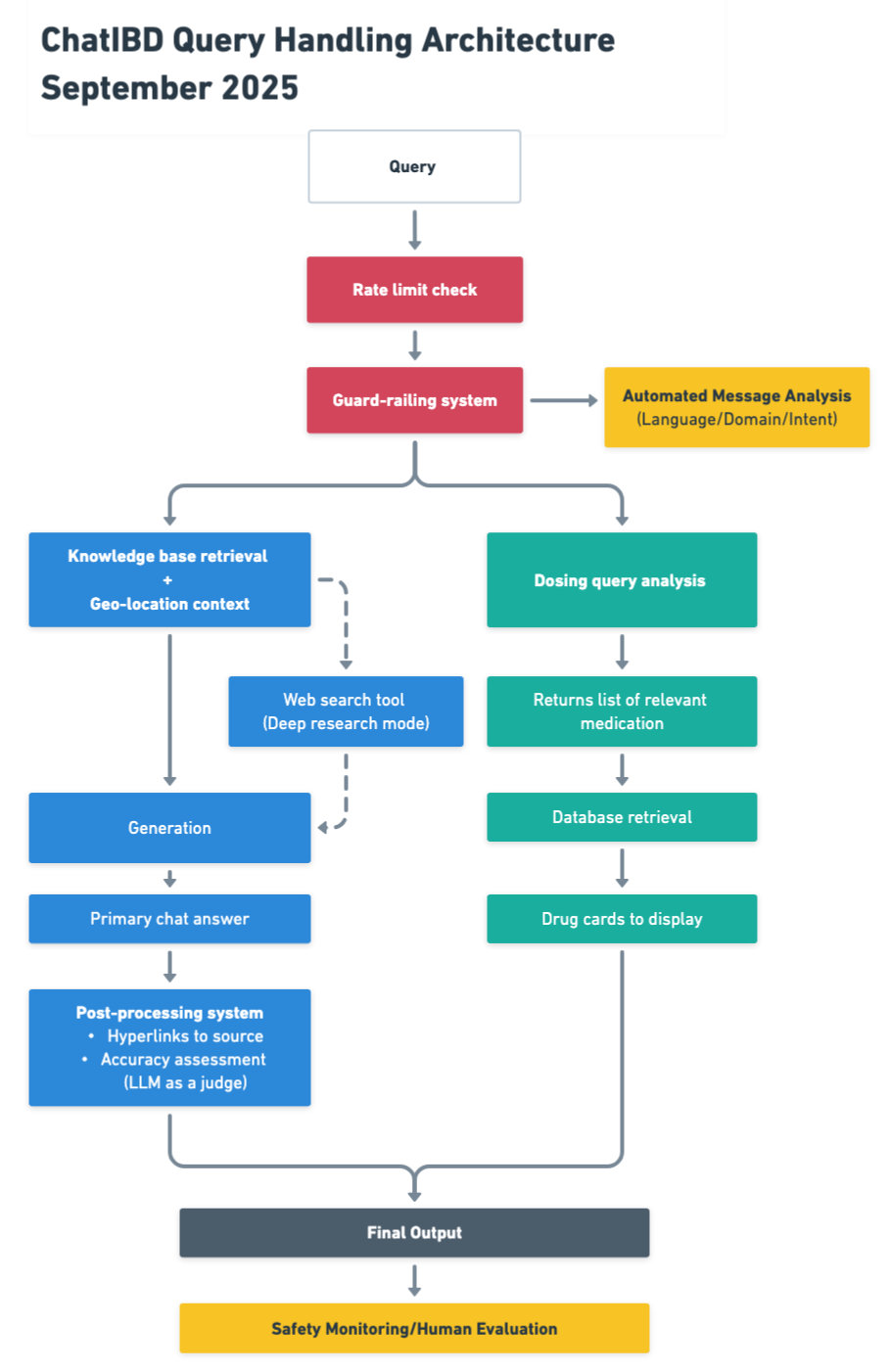
On top of this, ChatIBD runs parallel AI workflows (Figure 1): one specifically optimised for drug dosing queries and another for guideline retrieval. The result is evidence-based recommendations with reliable dosing information. This layered design turns a general-purpose model into a specialised clinical assistant.
Figure 1 ChatIBD Query Handling Architecture (click to open image in new tab)
Understanding the Context Window
At the heart of every large language model is the context window, the space where the model can “see” text at once. You can think of it like the whiteboard in a seminar room: everything written on it is visible to the model, and everything erased is forgotten. When you ask ChatGPT a question, the prompt plus the conversation history all live inside this window. Once you exceed its limit, older content gets pushed out and lost. LLMs therefore can sound intelligent but behave as if they have amnesia.
This limitation matters in clinical applications. If a model only sees the last few exchanges, it may forget the details you gave earlier or lose track of which guideline you are asking about. And even if the model has been trained on the entire internet, it cannot recall specific facts unless they are reintroduced into the context window at the time of the query.
ChatIBD is designed around this constraint. Instead of treating the context window as a black box, we deliberately fill it with information most relevant to your question. That way, when the model reasons, it works with the right material rather than relying on memory.
Tool Calling with Modern LLMs
Modern LLMs can be configured to recognise when a query should trigger a specialised tool. In healthcare, this technique can be used to ground models in accurate information.
In ChatIBD, we use this to run separate reasoning paths. When the query is about drug dosing, ChatIBD uses the dosing tool connected to a curated database of IBD medications to surface accurate information. The main query is routed through a model that activates a retrieval tool to surfaces the most relevant extracts from guidelines. In addition, you can also request that the model searches the web for the latest information, which is particularly useful when there is no answer within published guidelines, for example, questions about rare side effects of very new medications where data is limited.
Architecturally, you can think of this as parallel workflows:
- The dosing workflow ensures accuracy and prevents hallucinated numbers.
- The guideline workflow ensures recommendations are evidence-based and locally relevant.
- An optional web search tool saves you time by automating literature and online search.
- The orchestration layer integrates these outputs into the chat interface, improving efficiency.
This separation of concerns mirrors clinical practice itself. Dosing decisions come from formularies, treatment choices come from guidelines, and the clinician integrates them for patient care. ChatIBD encodes that logic into an AI-native architecture.
Safety Monitoring with Human in the Loop
Even with carefully designed workflows, no AI system should operate without oversight, especially in medicine. Large language models are powerful, but they remain fallible. That is why ChatIBD builds human-in-the-loop safety monitoring into its core.
At a technical level, this means every AI response can be reviewed and audited. We log which tools were called, which guideline extracts or dosing entries were used, and how the model combined them into an answer. This traceability ensures that if an unexpected output arises, we can see exactly what drove it and make targeted improvements.
On top of this, ChatIBD is designed for clinician feedback loops. Users can flag answers that are incorrect or potentially concerning. These reports are fed directly into our quality monitoring dashboards, and we review every single one of them.
The result is a layered safety net:
- Curated IBD guidelines ground the model and reduce the risk of hallucination.
- Parallel workflows for dosing ensure accuracy and mitigate the risks of single-point failures.
- Human oversight ensures continuous validation in real-world use.
Rather than replacing clinical judgment, ChatIBD complements it. The AI does the heavy lifting of retrieval and synthesis, while the clinician remains the final decision-maker.
Looking Ahead
By combining context-aware prompting, parallel tool workflows, and human-in-the-loop safety monitoring, ChatIBD is built for the realities of clinical decision support. Each layer addresses a specific weakness of general-purpose models, from context loss to hallucinated dosing to untraceable reasoning.
This is only the beginning. We plan to use the combination of these technologies and approaches to continuously improve ChatIBD’s performance on real-world queries. As more clinicians use the system, their feedback and interactions will help refine our retrieval strategies, expand our guideline coverage, and strengthen our dosing knowledge base. In this way, ChatIBD becomes not just a static tool but a learning system that grows safer, more accurate, and more useful with every query.